不会写代码的“鲸鱼哥”,被 DeepSeek 改写人生 | 专访 Hunter Bown
不会写代码的“鲸鱼哥”,被 DeepSeek 改写人生 | 专访 Hunter BownHunter Bown 没想到,自己会在差点因职业转型陷入困境后,被一个开源项目重新推回牌桌。
来自主题: AI资讯
9370 点击 2026-06-01 13:57
 搜索
搜索
Hunter Bown 没想到,自己会在差点因职业转型陷入困境后,被一个开源项目重新推回牌桌。
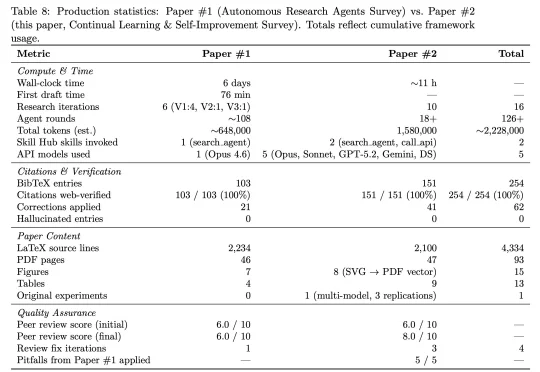
DeepSeek 研究员陈德里(Deli Chen)和 AI 合作的第二篇论文来了!论文地址:https://victorchen96.github.io/continual_learning_survey.pdf这篇论文聚焦 continual learning(持续学习) 与 self-iteration(自我迭代)。在陈德里看来,这是 AI 迈向 AGI 过程中极为关键的一步。

DeepSeek V4发布,比模型本身更受关注的,是一个根本性的转变: 国产算力生态正在从过去“芯片被动适配模型”的单向奔赴,迈向“芯模协同”的新阶段。

超越 GPT-5.5、Gemini 3.5 Flash、DeepSeek V4 Pro,阿里的最新旗舰模型 Qwen3.7 Max 在编程竞技榜拿下第二名,仅次于 Claude Opus 4.7。除了真实场景的用户选择,在传统的大模型固定评测榜单上,像是终端能力 Terminal Bench、编程能力 SWE Bench 等,Qwen3.7 Max 的表现也是拿下了国产模型的冠军。

最近,DeepSeek又刷屏了!

4个月烧光全年AI预算,天价Token账单正在屠杀硅谷!今天,高性能Agent模型SkyClaw-v1.0出世,性能直逼Opus 4.6、DeepSeek V4 Pro,百万上下文性价比拉满。
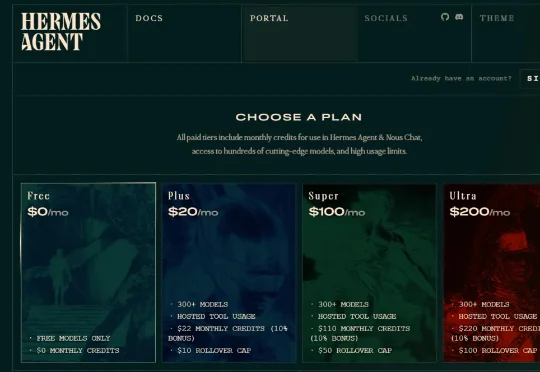
DeepSeek这半年生态铺得很快。现在好几个渠道可以免费或极低成本用上DeepSeek模型,从V4 Flash到V4 Pro都有。整理一下最实用的三条路。

DeepSeek 之于大模型,就像蜜雪冰城之于奶茶。你不必纠结性价比,因为它的本事你挑不出毛病,你的钱包它也从不为难。

最近人人都在聊 DeepSeek 的融资,这个等最终落定后我们再说。今天先说 Kimi 。

前两天,AI 圈子里出了个瓜,关于 DeepSeek TUI 创始人的,各个社媒群里几乎都刷屏了。但我发现一个问题 ——大家都只盯着一张微信群聊的截图在讨论,几乎没人把整件事的来龙去脉理一遍。